We often need for a design or a model to perform in a specified way. For example, the parameters in a nonlinear material model should be selected to best match the experimental stress-strain response. The geometrical parameters of a rubber bushing should be designed so that its force-deflection response matches the desired nonlinear stiffness behavior.
Optimization problems like these arise frequently. We refer to them as curve-fitting problems, because the goal is to minimize the difference between the specified target curve and the actual response curve
of our design or model.
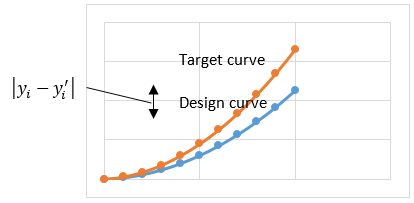
Figure 1. The difference between a target curve and a design curve is minimized in a curve fitting optimization problem.

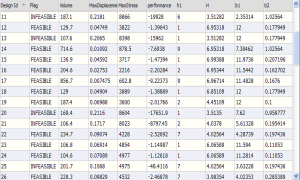 A common design scenario is to optimize the number and location of certain design features to satisfy performance goals and requirements. For the sake of discussion, let’s consider a specific example of this type of problem.
A common design scenario is to optimize the number and location of certain design features to satisfy performance goals and requirements. For the sake of discussion, let’s consider a specific example of this type of problem.