This new feature provides the ability to treat multiple computer resources as a single resource, without a job queuing system, to parallelize your HEEDS study. It allows for tremendous flexibility in the use and management of disparate computer resources.
As the name suggests, a compute resource set is a set of previously defined compute resources in HEEDS. The set allows you to define a pool of hardware resources that can be used to parallelize one or more analyses in the HEEDS study. The definition is not limited to homogeneous resources but can include any type of compute resource available. For example, a resource set could be a set of Windows workstations (as shown in the example image below), a set of Windows and Linux workstations, some workstations along with a cluster, several different clusters, etc. During the run, HEEDS will manage the job submissions to the resources defined in the set to make sure they are used effectively.
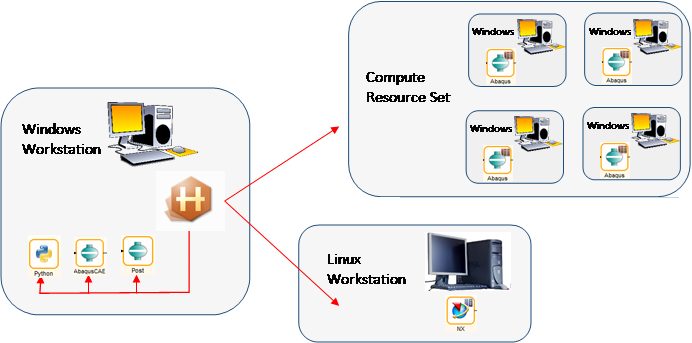
In the example shown below, several different compute resources are being used to execute the design process. The Python, Abaqus/CAE and Abaqus Post analyses are being run on the same Windows workstation as HEEDS MDO. The NX analysis is executed on a different compute resource, which is a Linux workstation. Finally, the Abaqus analysis simulations are being run on a compute resource set, which includes 4 different high-end Windows workstations. During the study execution, HEEDS will keep track of which resources are idle in the machine set for submitting a new analysis execution to ensure efficient use of resources in the set. HEEDS will manage all the connections and file staging during the study execution.

Using this features you can:
- Leverage multiple compute resources, not managed by a third-party scheduler, for design parallelization.
- Use idle workstations to run multiple jobs.
- Manage and balance parallelization between multiple analyses. For example, using this feature you can place a limit on the total number of jobs for AnalysisA + AnalysisB, independent of the number of parallel jobs defined individually for each analysis. This allows for the control of resources when they are hardware constrained, not software constrained.
- Increase the level of parallelization by making use of separate compute resources (for example, 1 cluster + 3 workstations).